Today Anthropic launched Claude Opus 4.7 making its newest flagship model generally available across Claude, its API, and major cloud platforms. The release focuses on better coding, sharper vision, and stronger long-context work at the same Opus 4.6 price. The more interesting subtext is safety: Anthropic is presenting Opus 4.7 as a capable public rollout before the broader arrival of more powerful Mythos-class systems.

- Claude Opus 4.7 is generally available as of April 16, 2026.
- The API model ID is
claude-opus-4-7, with a 1M-token context window and 128k max output. - Anthropic says the biggest gains are in coding, vision, memory, and long-running agent work.
- Pricing stays at $5 per million input tokens and $25 per million output tokens.
- The model is available on Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
- Mythos Preview is real, but still restricted; Opus 4.7 is the safer public step before that class of model ships broadly.
What’s new in Opus 4.7
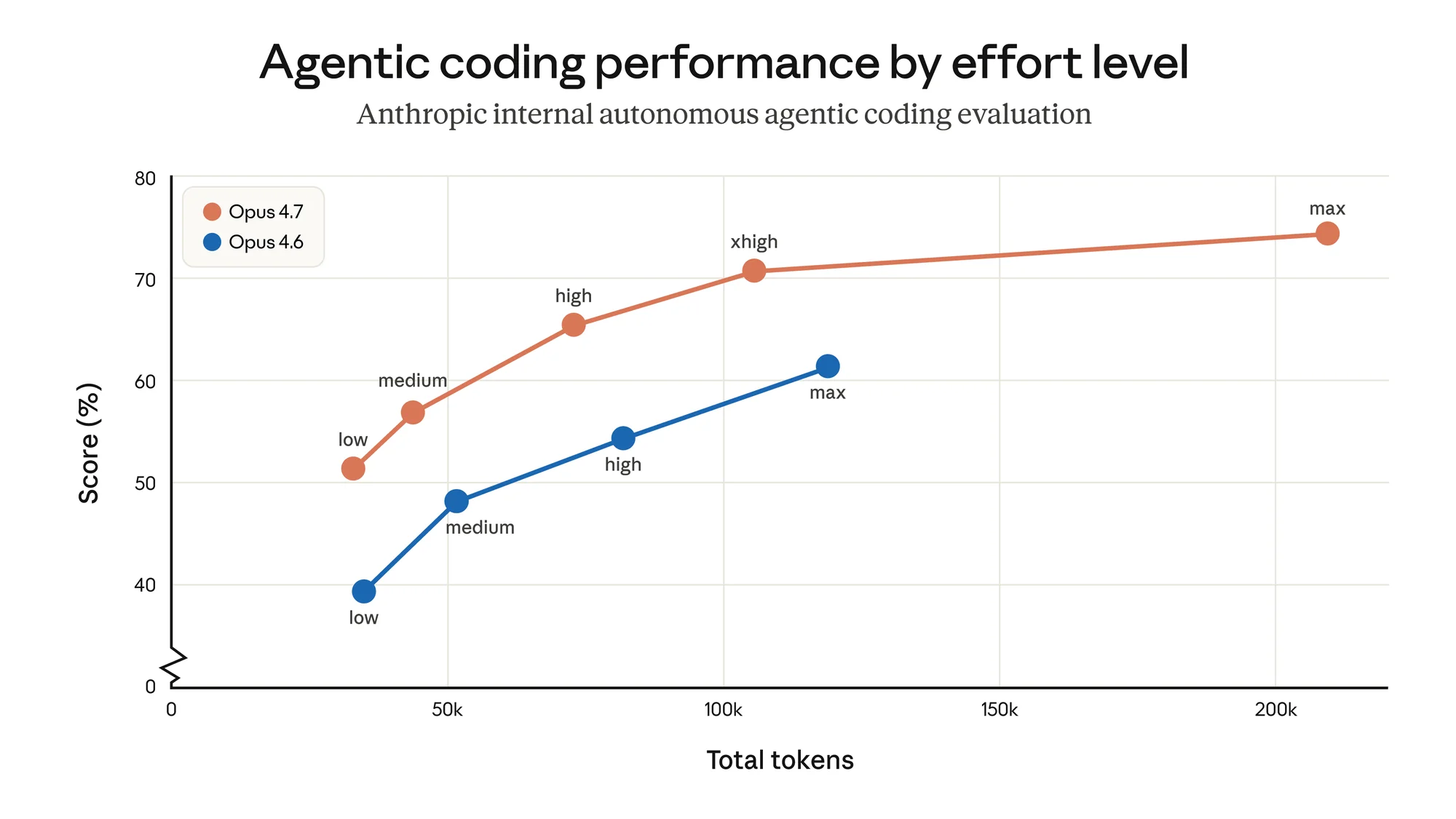
The center of the release is coding. Anthropic says Opus 4.7 improves across software engineering tasks, terminal use, and agentic workflows where the model has to plan, execute, inspect mistakes, and keep going. Modern coding assistants are no longer just autocomplete tools; they are expected to behave like long-session collaborators.
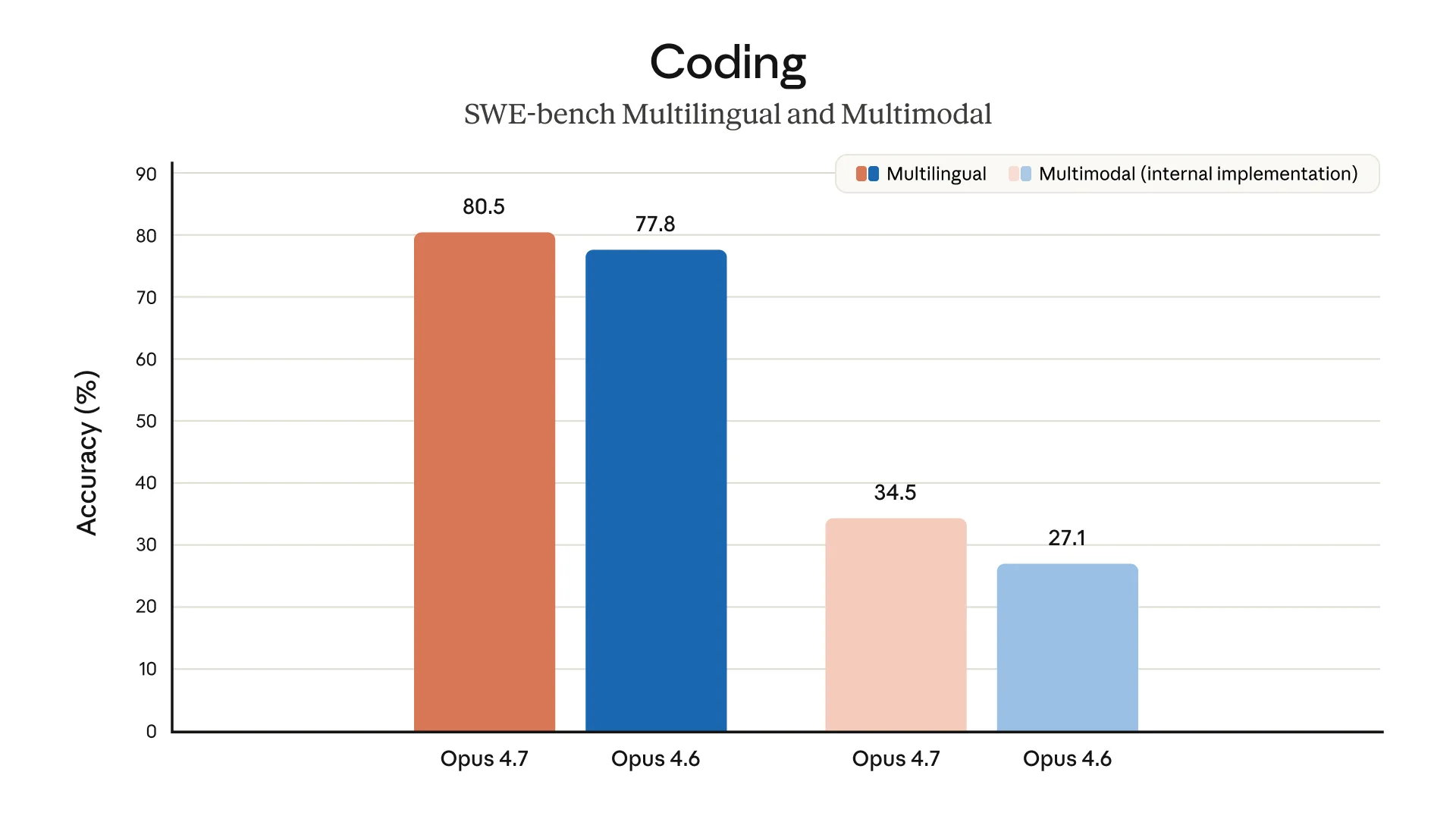
The customer anecdotes point in the same direction. Cursor says Opus 4.7 cleared 70% on CursorBench, compared with 58% for Opus 4.6. Clarence Huang, Anthropic’s VP of Technology, says the model “catches its own logical faults,” a useful trait when an agent is editing a real codebase.
Opus 4.7 also gets improved file-system-based memory for multi-session work. In plain English, Anthropic is trying to make Claude better at remembering what it has already learned from a project without forcing users to constantly restate context. That pairs naturally with long-running coding agents, research workflows, and internal tools.
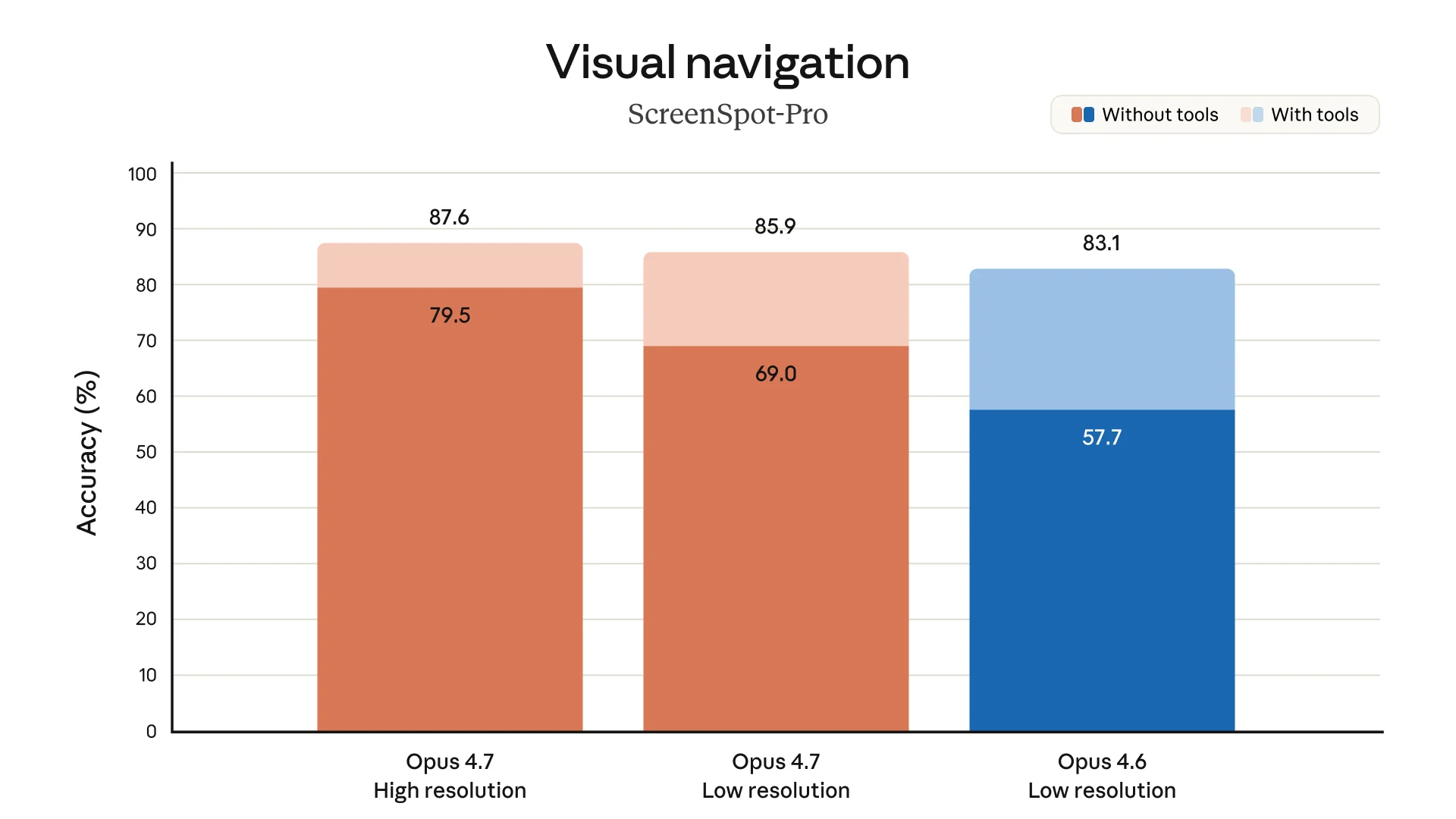
Vision is the other clear upgrade. Opus 4.7 supports higher-resolution images up to a 2576-pixel long edge, or roughly 3.75 megapixels, which Anthropic says is three times prior Claude models. That should help with chart reading, UI inspection, and document analysis.
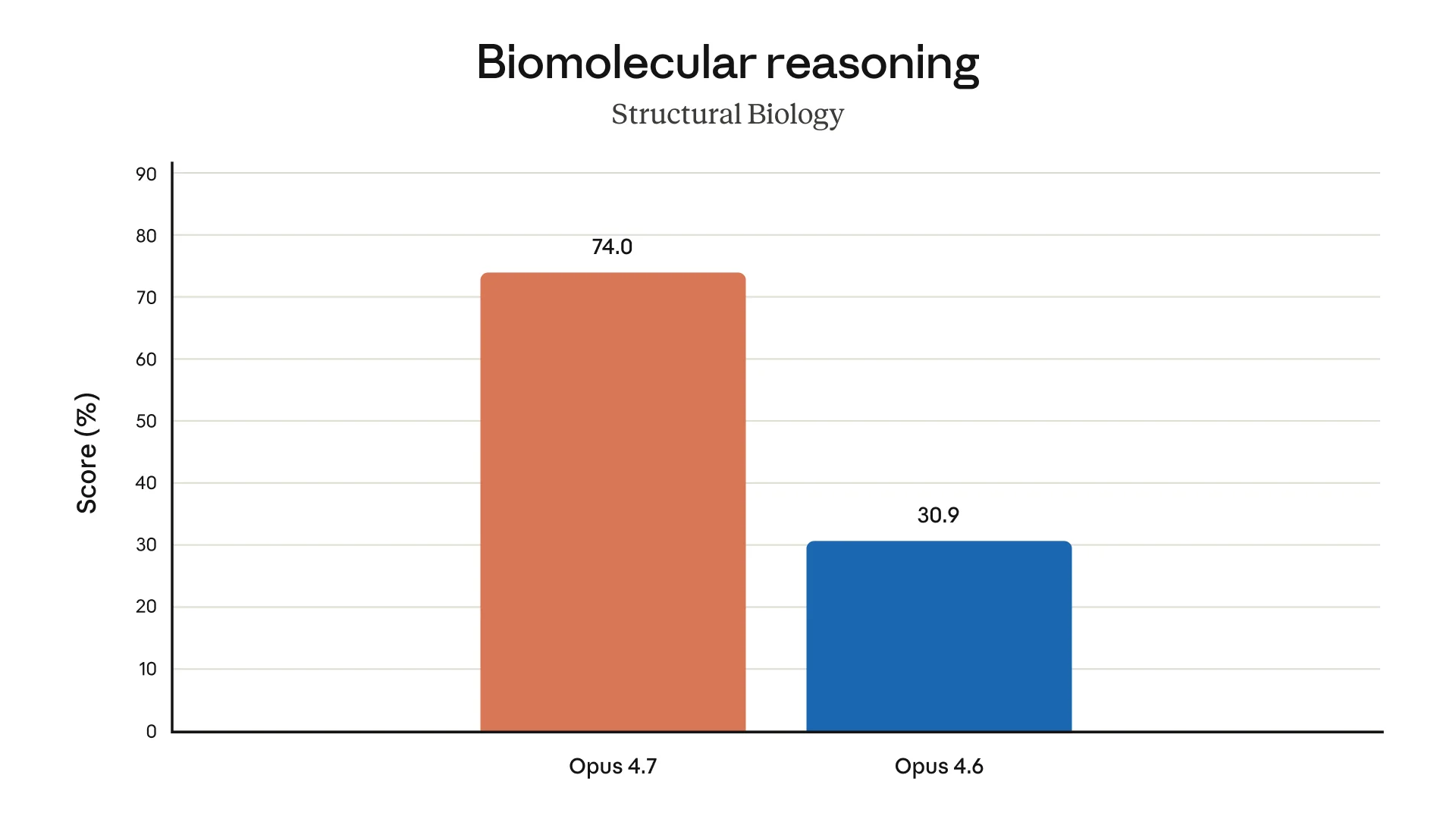
Beyond coding: Anthropic also highlights a structural biology result, where Opus 4.7 scores 74.0% versus 30.9% for Opus 4.6. That is a big jump on paper, though still best read as a benchmark signal rather than proof that the model is ready for unsupervised scientific work.
The benchmarks
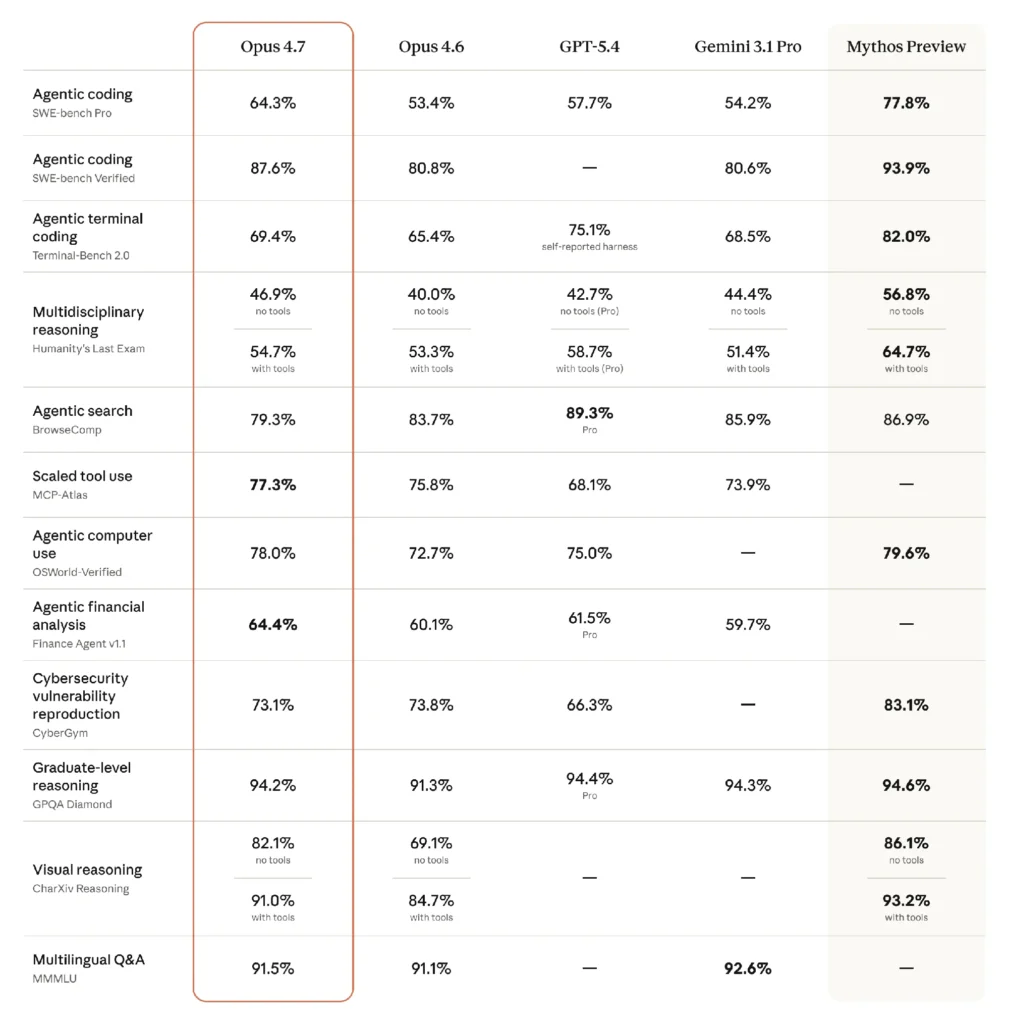
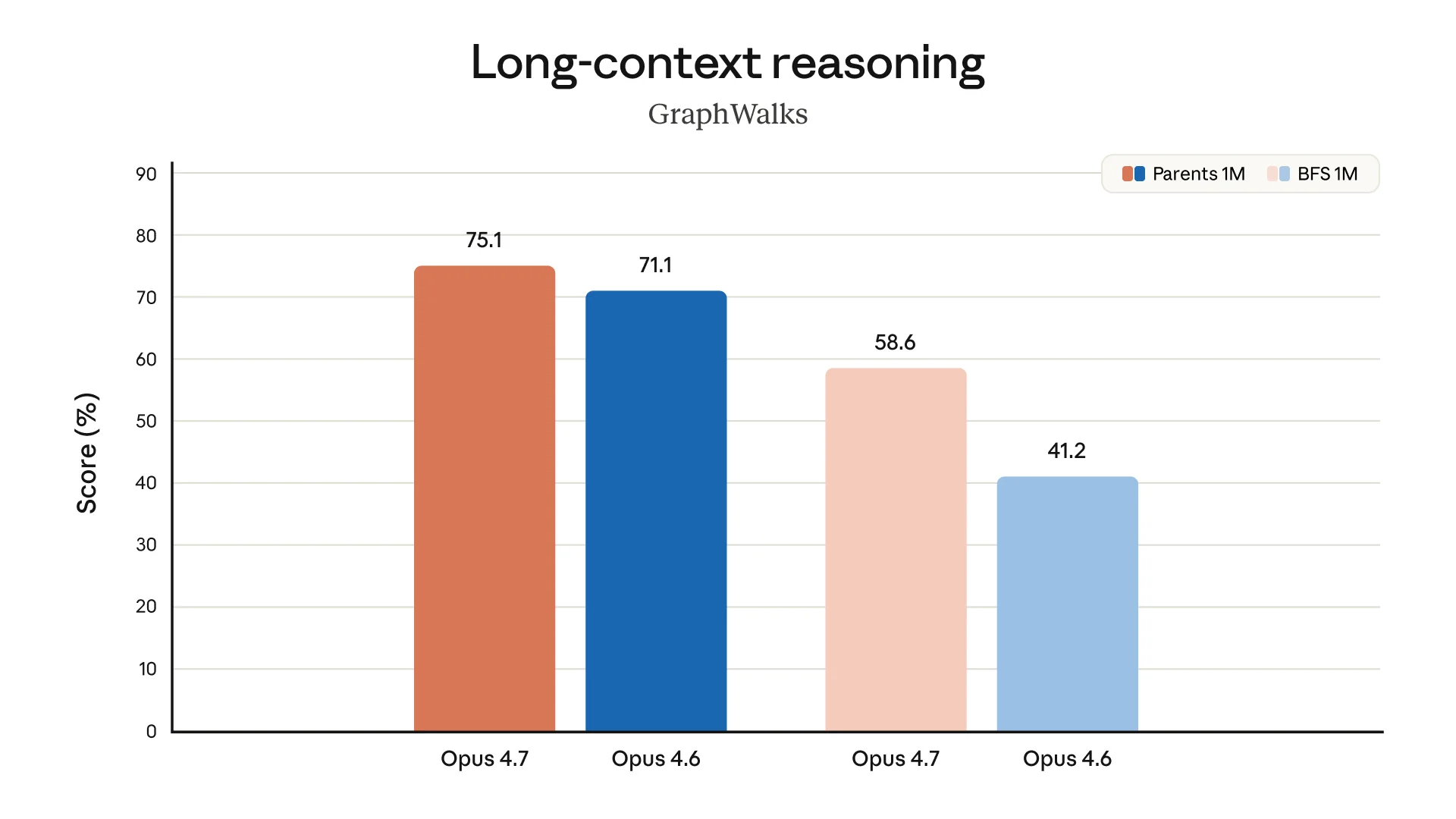
The main benchmark matrix shows broad gains over Opus 4.6. Opus 4.7 reaches 64.3% on SWE-bench Pro versus 53.4% for Opus 4.6, and 87.6% on SWE-bench Verified versus 80.8%. It also beats GPT-5.4 on SWE-bench Pro, Humanity’s Last Exam without tools, MCP-Atlas, OSWorld-Verified, and Finance Agent v1.1. Against Gemini 3.1 Pro, it leads on SWE-bench Pro, SWE-bench Verified, Terminal-Bench 2.0, both Humanity’s Last Exam variants, MCP-Atlas, and Finance Agent.
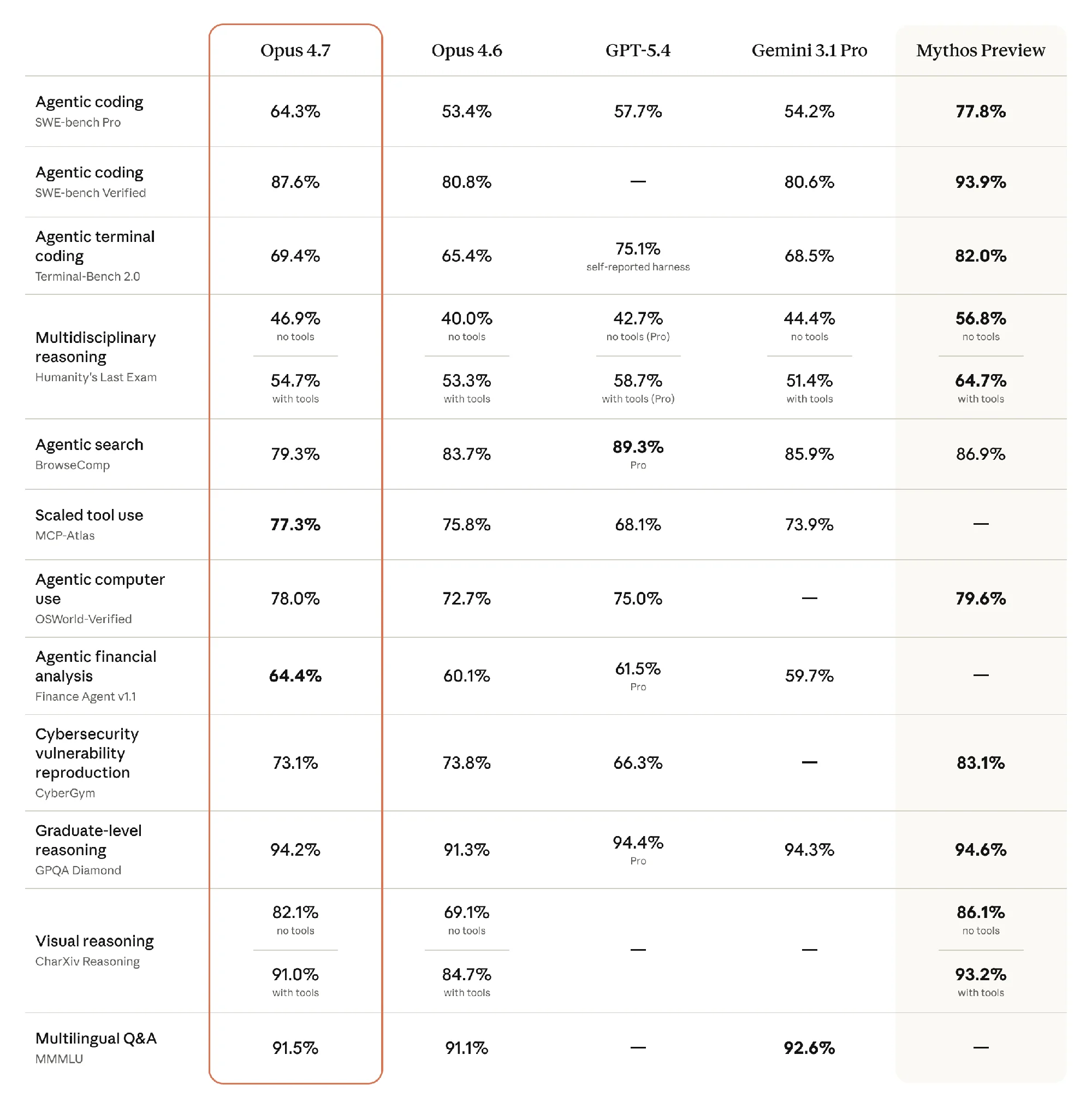
The caveats are worth spelling out. BrowseComp is not a win: Opus 4.7 scores 79.3%, below Opus 4.6, GPT-5.4 Pro, Gemini 3.1 Pro, and Mythos Preview. CyberGym is mixed too. Opus 4.7 beats GPT-5.4 there, but slips slightly from Opus 4.6 and remains far behind Mythos Preview.
Customer results add color. XBOW says Opus 4.7 scored 98.5% on its visual-acuity benchmark, versus 54.5% for Opus 4.6. Hex calls it the “strongest model Hex has evaluated,” while Cursor’s 70% CursorBench result suggests the coding gains are showing up outside Anthropic’s own charts.
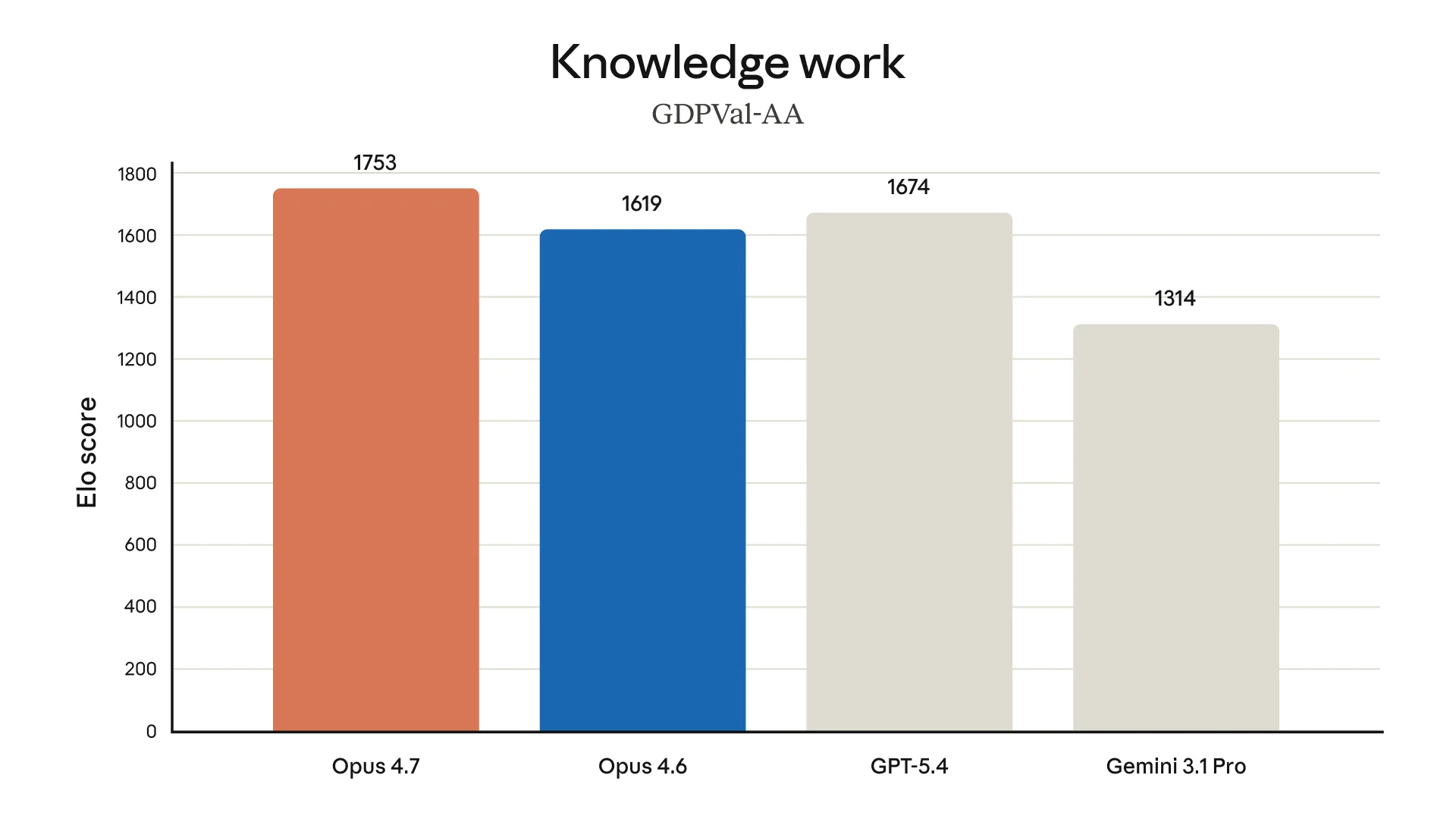
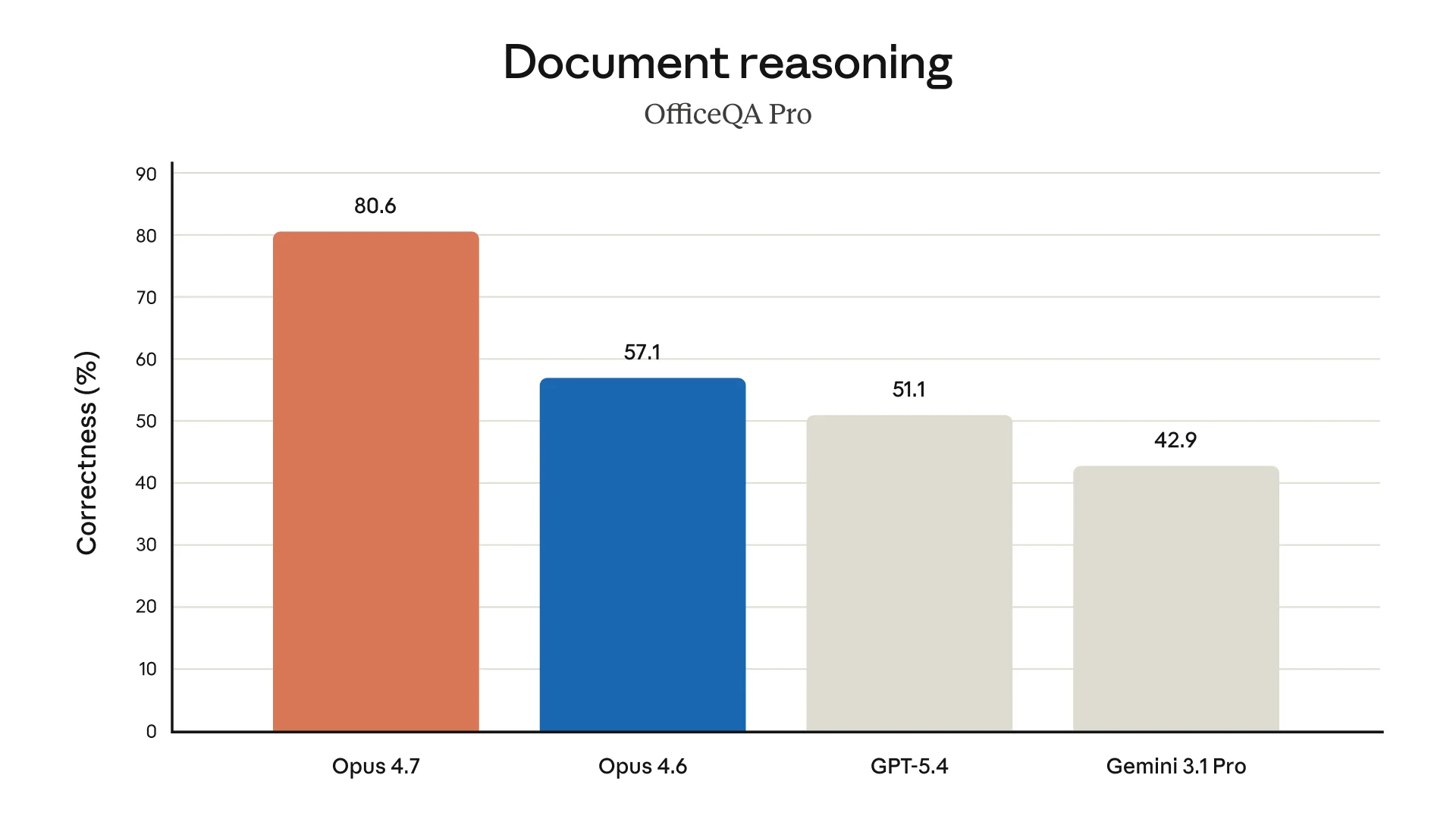
Enterprise-style benchmarks look especially strong. GDPVal-AA Elo rises to 1753, ahead of Opus 4.6 at 1619, GPT-4 at 1674, and Gemini 3.1 Pro at 1314. OfficeQA Pro correctness jumps to 80.6%, compared with 57.1% for Opus 4.6.
Pricing and availability
Opus 4.7 is available now to Claude Pro, Max, Team, and Enterprise users. Developers can call it through the Claude API as claude-opus-4-7, and Anthropic says it is also available through Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
The model has a 1M-token context window, a 128k-token max output, and a January 2026 knowledge cutoff. Standard pricing is unchanged from Opus 4.6: $5 per million input tokens and $25 per million output tokens. Batch pricing is $2.50 in and $12.50 out. Prompt caching is $6.25 for a five-minute write, $10 for a one-hour write, and $0.50 for cache hits or refreshes. US-only inference carries a 1.1x multiplier.
The Mythos question – is Opus 4.8 or Claude 5 next?
Speculation, clearly labeled: Mythos Preview is real, but Anthropic has not said it is Opus 5, Claude 5, or even the next public Claude model. Anthropic has said Mythos Preview is a general-purpose, unreleased frontier model central to Project Glasswing, is more capable than Opus 4.7, and has found “thousands of zero-day vulnerabilities” in that context. Access is being restricted for cyber reasons.
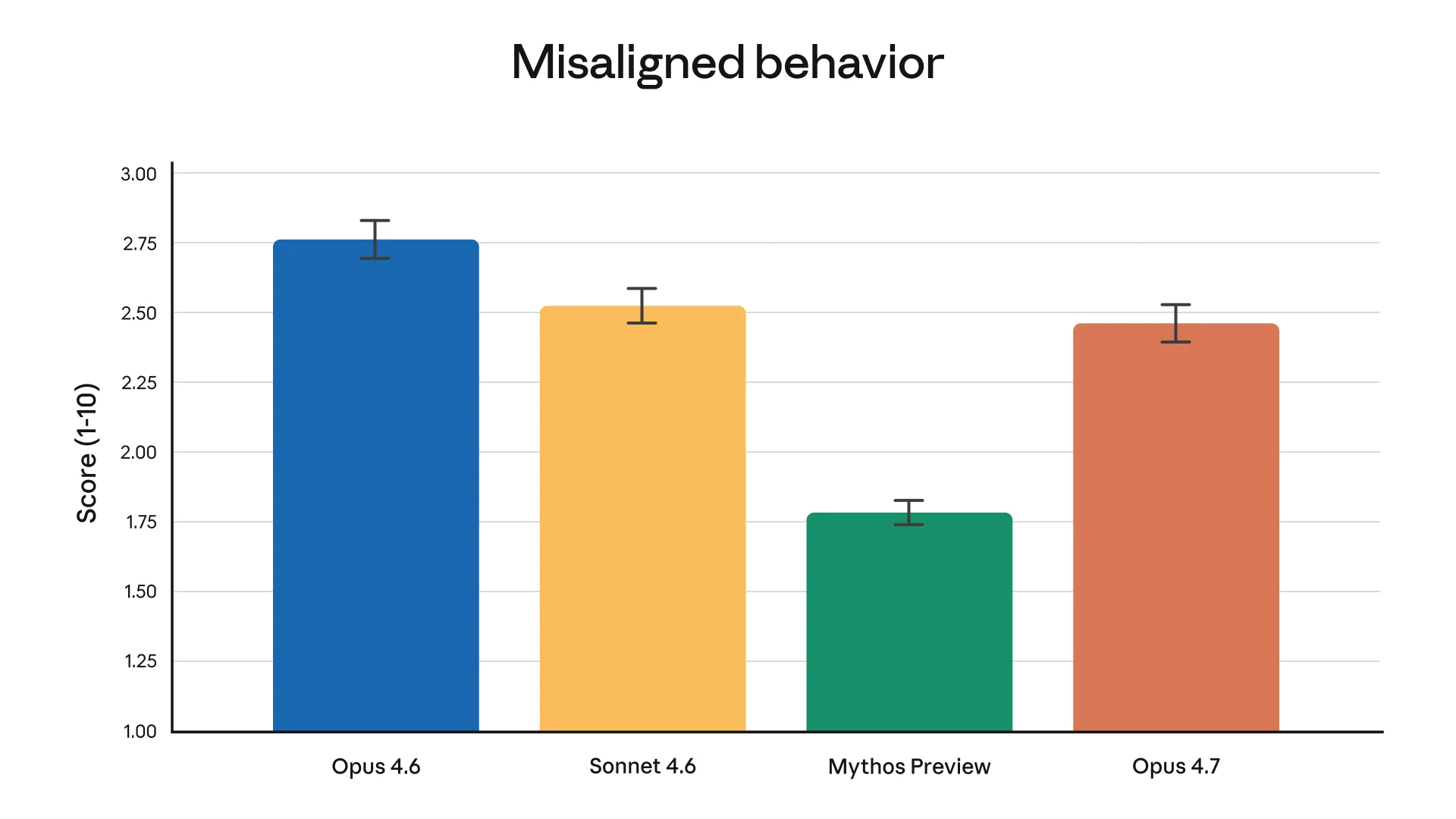
That makes the naming question interesting. In the Opus 4.7 announcement, Anthropic explicitly frames this model as a less capable system used to test safeguards before the broad release of Mythos-class models. The Verge picked up the same capability-frontier framing. Before launch, The Information reported via Techmeme that Anthropic was preparing Opus 4.7 and a design tool for release as soon as that week, while a Bloomberg item via Techmeme said the U.S. Treasury CIO had sought access to Mythos.
If Mythos ships broadly with scores close to the preview numbers, Anthropic may decide the jump is big enough for Opus 4.8, Opus 5, or Claude 5 branding. But that is still a naming bet, not a fact. For now, Opus 4.7 is the public model, and Mythos is the restricted signal of what may come next.
What to watch next: whether developers feel the coding gains in real repositories, whether memory holds up across long projects, and how quickly Anthropic moves from controlled Mythos access to broader release.